")
Phần lớn hệ thống cơ sở dữ liệu hiện nay đều được xây dựng bằng mô hình dữ liệu quan hệ. Vậy mô hình dữ liệu quan hệ là gì và có những đặc điểm nào. Bài viết dưới đây sẽ cung cấp cái nhìn bao quát, căn bản nhất về khái niệm này.
Mô hình dữ liệu quan hệ là gì?
Mô hình Dữ liệu Quan hệ (Relational Data Model – RDM) lần đầu tiên được Ted Codd của IBM phát triển vào những năm 1970. Sau đó khoảng 10 năm, RDM chính thức được đưa vào triển khai thương mại nhằm mục đích lưu trữ và xử lý dữ liệu trong cơ sở dữ liệu. Sở dĩ RDM trở nên phổ biến như vậy chính bởi tính đơn giản trong sử dụng cơ sở dữ liệu, cũng như nền tảng hỗ trợ tốt cho các nhà phát triển.
Mô hình dữ liệu quan hệ biểu diễn cơ sở dữ liệu dưới dạng một tập hợp các quan hệ (bảng giá trị). Mỗi bảng giá trị có các cột và hàng được gọi lần lượt là thuộc tính (attributes) và bộ giá trị (tuples). Mỗi bộ giá trị (tuple) kí hiệu một thực thể hoặc mối quan hệ trong thế giới thực. Tên của quan hệ và tên của các thuộc tính sẽ góp phần giải thích ý nghĩa của từng bộ.
Về cơ bản, có thể hiểu RDM dựa trên một số điểm chính sau đây:
- Cơ sở dữ liệu là một tập hợp các quan hệ có liên quan (bảng giá trị).
- Mỗi quan hệ có một tên gọi riêng cho biết loại tuple (bộ dữ liệu) mà quan hệ có.
- Mỗi quan hệ có một tập hợp các thuộc tính (tên cột) đại diện cho các tính chất hoặc các đặc trưng của từng thực thể.
- Một bộ – tuple (hàng) biểu diễn một thực thể với các các giá trị tương ứng với từng thuộc tính.
- Mỗi cột trong bảng còn được gọi là một trường (field)

Đặc điểm của mô hình cơ sở dữ liệu quan hệ.
Một cơ sở dữ liệu có thể chứa một số lượng nhất định các quan hệ. Để giảm thiểu tối đa trường hợp sai sót, mỗi quan hệ phải được xác định là duy nhất. Dưới đây là một số đặc điểm giúp tự động phân biệt các quan hệ trong cơ sở dữ liệu
1. Mỗi quan hệ trong cơ sở dữ liệu phải có một tên riêng biệt và duy nhất để phân biệt nó với các quan hệ khác trong cơ sở dữ liệu.
2. Một quan hệ không được có hai thuộc tính trùng tên. Mỗi thuộc tính phải có một tên riêng biệt.
3. Trong một quan hệ không được xuất hiện các bộ giá trị trùng lặp.

4. Mỗi bộ phải có chính xác một giá trị dữ liệu cho một thuộc tính.
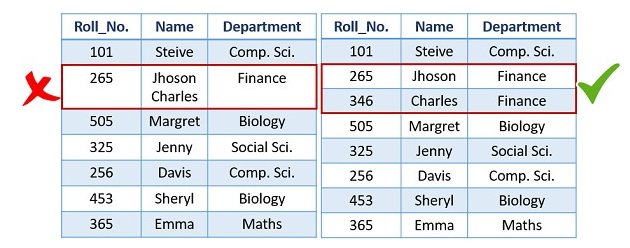
5. Các bộ (tuples) hay các thuộc tính (attributes) trong một quan hệ đều không nhất thiết phải tuân theo một thứ tự nhất định
Các ràng buộc của mô hình quan hệ.
Ràng buộc chính là những hạn chế được chỉ định cho các giá trị dữ liệu trong cơ sở dữ liệu quan hệ. Có thể kể đến các ràng buộc chính như sau:
- Inherent Model-Based Constraints (Ràng buộc dựa trên mô hình vốn có). Ví dụ, một quan hệ trong cơ sở dữ liệu không được có các bộ giá trị trùng lặp, tuy nhiên, không có bất cứ ràng buộc nào trong thứ tự của các bộ giá trị và thuộc tính.
- Schema-Based Constraints (Ràng buộc dựa trên lược đồ) Các ràng buộc được chỉ định trong khi xác định lược đồ của cơ sở dữ liệu sử dụng DDL là các ràng buộc dựa trên lược đồ. Chúng được phân loại cụ thể thành ràng buộc miền, ràng buộc khóa, ràng buộc tính toàn vẹn thực thể, ràng buộc toàn vẹn tham chiếu và ràng buộc trên giá trị rỗng
- Application-based Constraints (Ràng buộc dựa trên ứng dụng): Các ràng buộc không thể áp dụng trong khi xác định lược đồ cơ sở dữ liệu sẽ được thể hiện trong các chương trình ứng dụng.
(Nguồn tham khảo: Binary Terms)